
Google Bard: هر آنچه که باید بدانید

Google به تازگی Bard، پاسخ آن به ChatGPT، و کاربران با آن آشنا می شوند تا ببینند که چگونه با چت ربات مبتنی بر هوش مصنوعی OpenAI مقایسه می شود.
نام “Bard” صرفاً مبتنی بر بازاریابی است، زیرا هیچ الگوریتمی به نام Bard وجود ندارد، اما ما میدانیم که چت بات توسط LaMDA پشتیبانی میشود.
در اینجا همه چیزهایی است که تاکنون درباره بارد میدانیم و برخی تحقیقات جالب که ممکن است ایدهای درباره نوع الگوریتمهایی ارائه دهد که ممکن است بارد را تقویت کند.
Google Bard چیست؟
Bard یک ربات گفتگوی آزمایشی Google است که توسط مدل زبان بزرگ LaMDA پشتیبانی میشود.


این یک هوش مصنوعی مولد است که درخواستها را میپذیرد و کارهای مبتنی بر متن مانند ارائه پاسخها و خلاصهها و ایجاد اشکال مختلف محتوا را انجام میدهد.
بارد همچنین با خلاصه کردن اطلاعات موجود در اینترنت و ارائه پیوندهایی برای کاوش در وبسایتهایی با اطلاعات بیشتر، به کاوش موضوعات کمک میکند.
چرا Google Bard را منتشر کرد؟
Google Bard را پس از راهاندازی بسیار موفق OpenAI’s ChatGPT منتشر کرد، که این تصور را ایجاد کرد که Google از نظر فناوری عقب مانده بود.
ChatGPT به عنوان یک فناوری انقلابی با پتانسیل ایجاد اختلال در صنعت جستجو و تغییر توازن قدرت از جستجوی Google و کسبوکار تبلیغاتی پردرآمد جستجو تلقی شد.
در 21 دسامبر 2022، سه هفته پس از راه اندازی ChatGPT، نیویورک تایمز گزارش داد که گوگل یک “کد قرمز” اعلام کرده است تا به سرعت پاسخ خود را به تهدیدی که برای مدل کسبوکارش ایجاد میکند، مشخص کند.
چهل و هفت روز پس از تعدیل استراتژی کد قرمز، Google راهاندازی Bard را در ۶ فوریه ۲۰۲۳ اعلام کرد.
مشکل Google Bard چه بود؟
اعلام Bard یک شکست خیره کننده بود زیرا نسخه ی نمایشی که قرار بود ربات چت گوگل را به نمایش بگذارد حاوی یک خطای واقعی است.
عدم دقت هوش مصنوعی Google آنچه را که به معنای بازگشت پیروزمندانه بود، به شکلی به شکل یک کیک متواضع تبدیل کرد.
اشتراکهای Google متعاقبا صد میلیارد دلار از ارزش بازار خود را در یک روز از دست داد، که نشان دهنده از دست دادن اعتماد به توانایی Google برای پیمایش در عصر آینده هوش مصنوعی است.
Google Bard چگونه کار می کند؟
Bard از نسخه “سبک” LaMDA نیرو می گیرد.
LaMDA یک مدل زبان بزرگ است که بر روی مجموعه داده های متشکل از گفتگوی عمومی و داده های وب آموزش داده شده است.
دو عامل مهم در رابطه با آموزش شرح داده شده در مقاله تحقیقاتی مرتبط وجود دارد که می توانید آنها را به صورت PDF از اینجا دانلود کنید: LaMDA: مدلهای زبان برای برنامههای گفتگو (مطالعه چکیده اینجا).
- A. ایمنی: این مدل با تنظیم آن با داده هایی که توسط کارگران حاشیه نویسی شده است، به سطح ایمنی دست می یابد.
- B. زمینه سازی: LaMDA خود را به طور واقعی با منابع دانش خارجی (از طریق بازیابی اطلاعات، که جستجو است) استوار می کند.
مقاله تحقیقاتی LaMDA بیان میکند:
“…پایهبندی واقعی، شامل توانمندسازی مدل برای مشورت با منابع دانش خارجی، مانند یک سیستم بازیابی اطلاعات، یک مترجم زبان، و یک ماشینحساب است.
ما واقعیت را با استفاده از یک معیار مبنایی بودن کمیت میکنیم، و متوجه میشویم که رویکرد ما به مدل امکان میدهد تا به جای پاسخهایی که صرفاً معقول به نظر میرسند، پاسخهایی مبتنی بر منابع شناختهشده تولید کند.»
Google از سه معیار برای ارزیابی خروجیهای LaMDA استفاده کرد:
- حساسیت: اندازه گیری اینکه آیا پاسخ منطقی است یا نه.
- ویژگی: اگر پاسخ مخالف کلی/مبهم یا از نظر زمینه خاص باشد، اندازه گیری می کند.
- جالب بودن: این معیار اندازه گیری می کند که پاسخ های LaMDA روشنگر باشد یا کنجکاوی را برانگیزد.
هر سه معیار توسط ارزیابهای جمعسپاری مورد قضاوت قرار گرفتند و این دادهها برای ادامه بهبود آن به دستگاه بازگردانده شدند.
مقاله تحقیقاتی LaMDA با بیان اینکه بررسیهای جمعسپاری و توانایی سیستم برای بررسی واقعیت با موتور جستجو، تکنیکهای مفیدی بودند، به پایان میرسد.
محققان Google نوشتند:
“ما دریافتیم که داده های حاشیه نویسی شده توسط جمعیت ابزار موثری برای ایجاد دستاوردهای اضافی قابل توجه است.
ما همچنین دریافتیم که فراخوانی APIهای خارجی (مانند یک سیستم بازیابی اطلاعات) مسیری را به سوی بهبود قابل توجهی ارائه میدهد، که ما آن را بهعنوان میزانی تعریف میکنیم که پاسخ تولید شده حاوی ادعاهایی است که میتوان آنها را با منبع شناخته شده ارجاع داد و بررسی کرد. ”
برنامهریزی Google برای استفاده از Bard در جستجو چگونه است؟
آینده Bard در حال حاضر به عنوان یک ویژگی در جستجو متصور است.
اعلان Google در فوریه به اندازه کافی در مورد نحوه اجرای Bard مشخص نبود.
جزئیات کلیدی در یک پاراگراف نزدیک به انتهای اعلامیه وبلاگ Bard، جایی که به عنوان یک ویژگی هوش مصنوعی در جستجو توصیف شد، دفن شد.
این عدم وضوح این تصور را تقویت کرد که بارد در جستجو ادغام خواهد شد، که هرگز چنین نبود.
اطلاعیه Google در فوریه 2023 از بارد بیان می کند که گوگل در برخی موارد ویژگی های هوش مصنوعی را در جستجو ادغام می کند:
“به زودی، ویژگیهای مبتنی بر هوش مصنوعی را در جستجو خواهید دید که اطلاعات پیچیده و دیدگاههای متعدد را در قالبهای قابل هضم تقطیر میکند، بنابراین میتوانید به سرعت تصویر بزرگ را درک کنید و بیشتر بیاموزید. از وب: چه به دنبال دیدگاههای بیشتر باشد، مانند وبلاگهایی از افرادی که هم پیانو و هم گیتار مینوازند، یا عمیقتر کردن موضوع مرتبط، مانند مراحل شروع بهعنوان مبتدی.
این ویژگیهای جدید هوش مصنوعی به زودی در جستجوی Google عرضه میشوند.
واضح است که بارد در حال جستجو نیست. در عوض، قرار است یک ویژگی در جستجو باشد و نه جایگزینی برای جستجو.
ویژگی جستجو چیست؟
یک ویژگی چیزی شبیه به پانل دانش Google است که اطلاعات دانشی درباره افراد، مکانها و چیزهای قابل توجه ارائه میدهد.
صفحه وب «جستجو چگونه کار می کند” درباره ویژگی ها توضیح می دهد:
“ویژگیهای جستجوی Google تضمین میکند که اطلاعات مناسب را در زمان مناسب در قالبی که برای درخواست شما مفیدتر است، دریافت میکنید.
گاهی اوقات یک صفحه وب است و گاهی اوقات اطلاعات واقعی مانند نقشه یا موجودی در یک فروشگاه محلی است.”
در یک جلسه داخلی در Google (گزارش شده توسط CNBC)، کارمندان استفاده از Bard در جستجو را زیر سوال بردند.
یکی از کارمندان اشاره کرد که مدل های زبان بزرگ مانند ChatGPT و Bard منابع اطلاعاتی مبتنی بر واقعیت نیستند.
کارمند Google پرسید:
“چرا فکر می کنیم اولین برنامه بزرگ باید جستجو باشد، که در قلب آن یافتن اطلاعات واقعی است؟”
Jack Krawczyk، مدیر محصول Google Bard، پاسخ داد:
“فقط میخواهم خیلی واضح بگویم: بارد جستجو نیست.”
در همان رویداد داخلی، الیزابت رید، معاون مهندسی گوگل برای جستجو، تکرار کرد که بارد در حال جستجو نیست.
او گفت:
“Bard واقعا از جستجو جداست…”
آنچه می توانیم با اطمینان نتیجه بگیریم این است که Bard تکرار جدیدی از جستجوی گوگل نیست. این یک ویژگی است.
بارد یک روش تعاملی برای کاوش موضوعات است
اعلام Bard توسط Google کاملاً صریح بود که Bard جستجوگر نیست. این بدان معنی است که، در حالی که سطح جستجو به پاسخها پیوند میدهد، Bard به کاربران کمک میکند تا دانش را بررسی کنند.
اعلامیه توضیح می دهد:
“وقتی مردم به Google فکر می کنند، اغلب به این فکر می کنند که برای پاسخ های واقعی سریع به ما مراجعه کنند، مانند “یک پیانو چند کلید دارد؟”
اما به طور فزایندهای، مردم برای دریافت بینش و درک عمیقتر به Google روی میآورند – مثلاً «آیا یادگیری پیانو یا گیتار آسانتر است و هر کدام چقدر تمرین نیاز دارند؟»
یادگیری درباره موضوعی مانند این میتواند به تلاش زیادی نیاز داشته باشد تا بفهمید واقعاً چه چیزی باید بدانید، و مردم اغلب میخواهند طیف متنوعی از نظرات یا دیدگاهها را بررسی کنند.”
در نظر گرفتن Bard به عنوان یک روش تعاملی برای دسترسی به دانش در مورد موضوعات، ممکن است مفید باشد.
اطلاعات وب نمونه های برد
مشکل مدلهای زبان بزرگ این است که پاسخها را تقلید میکنند، که میتواند منجر به خطاهای واقعی شود.
محققانی که LaMDA را ایجاد کردهاند بیان میکنند که رویکردهایی مانند افزایش اندازه مدل میتواند به آن کمک کند اطلاعات واقعی بیشتری به دست آورد.
اما آنها خاطرنشان کردند که این رویکرد در مناطقی که واقعیت ها به طور مداوم در طول زمان در حال تغییر هستند، شکست می خورد، که محققان از آن به عنوان “مشکل تعمیم زمانی” یاد می کنند.
تازگی به معنای اطلاعات به موقع را نمی توان با یک مدل زبان ثابت آموزش داد.
راه حلی که LaMDA دنبال کرد، پرس و جو در سیستم های بازیابی اطلاعات بود. یک سیستم بازیابی اطلاعات یک موتور جستجو است، بنابراین LaMDA نتایج جستجو را بررسی می کند.
به نظر میرسد این ویژگی از LaMDA یکی از ویژگیهای Bard باشد.
اعلامیه Google Bard توضیح می دهد:
“بارد به دنبال ترکیب وسعت دانش جهان با قدرت، هوش و خلاقیت مدلهای بزرگ زبان ما است.
از اطلاعات وب استفاده میکند تا پاسخهای تازه و باکیفیت ارائه کند.”
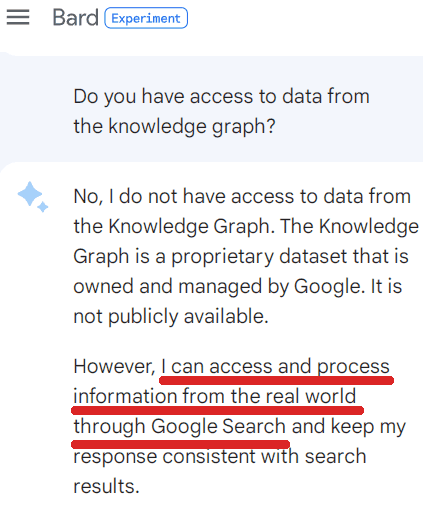 عکس از صفحه چت Google Bard، مارس 2023
عکس از صفحه چت Google Bard، مارس 2023LaMDA و (احتمالاً با فرمت) بارد با آنچه مجموعه ابزار (TS) نامیده می شود به این امر دست می یابند.
مجموعه ابزار در مقاله محقق LaMDA توضیح داده شده است:
“ما یک مجموعه ابزار (TS) ایجاد می کنیم که شامل یک سیستم بازیابی اطلاعات، یک ماشین حساب، و یک مترجم است.
TS یک رشته را به عنوان ورودی می گیرد و لیستی از یک یا چند رشته را خروجی می کند. هر ابزار در TS یک رشته را انتظار دارد و لیستی از رشته ها را برمی گرداند.
به عنوان مثال، ماشین حساب “135+7721” را می گیرد و فهرستی حاوی [“7856”] را به بیرون می دهد. به طور مشابه، مترجم میتواند «Hello in French» را بگیرد و [‘Bonjour’] را خروجی بگیرد.
در نهایت، سیستم بازیابی اطلاعات می تواند “رافائل نادال چند ساله است؟” و خروجی [“رافائل نادال / سن / 35”] را بگیرد.
سیستم بازیابی اطلاعات همچنین میتواند قطعاتی از محتوا را از وب باز به همراه URLهای مربوطه برگرداند.
TS یک رشته ورودی را روی همه ابزارهای خود امتحان میکند، و یک لیست خروجی نهایی از رشتهها را با الحاق فهرستهای خروجی از هر ابزار به ترتیب زیر تولید میکند: ماشین حساب، مترجم، و سیستم بازیابی اطلاعات.
اگر ابزاری نتواند ورودی را تجزیه کند، فهرستی خالی از نتایج را برمیگرداند (به عنوان مثال، ماشینحساب نمیتواند «رافائل نادال چند ساله است؟» را تجزیه کند، و بنابراین در فهرست خروجی نهایی مشارکت نمیکند. /p>
در اینجا یک پاسخ Bard با یک قطعه از وب باز است:
 عکس از صفحه چت Google Bard، مارس 2023
عکس از صفحه چت Google Bard، مارس 2023سیستم های پرسش و پاسخ مکالمه
هیچ مقاله تحقیقاتی که نام “بارد” را ذکر کرده باشد وجود ندارد.
با این حال، تحقیقات اخیر کمی در رابطه با هوش مصنوعی، از جمله توسط دانشمندان مرتبط با LaMDA، وجود دارد که ممکن است بر بارد تأثیر بگذارد.
موارد زیر ادعا نمیکند که Google از این الگوریتمها استفاده میکند. نمیتوانیم به طور قطع بگوییم که هیچ یک از این فناوریها در Bard استفاده میشوند.
ارزش دانستن این مقالات تحقیقاتی در دانستن آنچه ممکن است است.
الگوریتمهای زیر مربوط به سیستمهای پاسخگویی به پرسش مبتنی بر هوش مصنوعی هستند.
یکی از نویسندگان LaMDA روی پروژه ای کار کرد که در مورد ایجاد داده های آموزشی برای یک سیستم بازیابی اطلاعات محاوره ای است.
میتوانید مقاله تحقیقاتی ۲۰۲۲ را بهصورت PDF از اینجا دانلود کنید: Dialog Inpainting: Turning Documents در Dialogs (و چکیده را در اینجا بخوانید).
مشکل آموزش سیستمی مانند Bard این است که مجموعه دادههای پرسش و پاسخ (مانند مجموعه دادههای متشکل از پرسشها و پاسخهای موجود در Reddit) محدود به نحوه رفتار افراد در Reddit است.
این شامل نحوه رفتار افراد خارج از آن محیط و انواع سؤالاتی که میپرسند و پاسخهای صحیح به آن سؤالات چه خواهد بود، نمیشود.
محققان ایجاد یک سیستم خواندن صفحات وب را کاوش کردند، سپس از “نقاشگر گفتگو” استفاده کردند تا پیشبینی کنند که هر قسمتی که دستگاه میخواند به چه سوالاتی پاسخ داده میشود.
بخشی از یک صفحه وب قابل اعتماد ویکیپدیا که میگوید: “آسمان آبی است” را میتوان به این سوال تبدیل کرد که “آسمان چه رنگی است؟”
محققان مجموعه داده پرسش و پاسخ خود را با استفاده از ویکیپدیا و سایر صفحات وب ایجاد کردند. آنها مجموعه داده ها را WikiDialog و WebDialog نامیدند.
- WikiDialog مجموعهای از پرسشها و پاسخهایی است که از دادههای ویکیپدیا مشتق شدهاند.
- WebDialog مجموعه داده ای است که از گفتگوی صفحه وب در اینترنت مشتق شده است.
این مجموعه داده های جدید 1000 برابر بزرگتر از مجموعه داده های موجود هستند. اهمیت آن در این است که به مدل های زبان مکالمه فرصتی برای یادگیری بیشتر می دهد.
محققان گزارش دادند که این مجموعه داده جدید به بهبود سیستمهای پاسخگویی به پرسش مکالمه تا بیش از 40% کمک کرده است.
مقاله پژوهشی موفقیت این رویکرد را شرح میدهد:
“مهمتر است، ما متوجه شدیم که مجموعه داده های نقاشی شده ما منابع قدرتمند داده های آموزشی برای سیستم های ConvQA هستند…
هنگامی که برای پیشآموزش معماریهای استاندارد بازیابی و رتبهبندی استفاده میشوند، آنها در سه معیار بازیابی ConvQA مختلف (QRECC، OR-QUAC، TREC-CAST) پیشرفتهتر هستند و تا 40 درصد سود نسبی را ارائه میکنند. معیارهای ارزیابی استاندارد…
بهطور قابلتوجهی، متوجه میشویم که فقط پیشآموزش در WikiDialog، عملکرد بازیابی صفر شات قوی را امکانپذیر میکند – تا 95٪ عملکرد یک بازیابی دقیق – بدون استفاده از دادههای ConvQA درون دامنه. “
آیا ممکن است Google Bard با استفاده از مجموعه دادههای WikiDialog و WebDialog آموزش دیده باشد؟
مشکل است که سناریویی را تصور کنید که در آن Google آموزش هوش مصنوعی مکالمهای را بر روی مجموعه دادهای که بیش از 1000 برابر بزرگتر است، منتقل کند.
اما ما به طور قطع نمی دانیم زیرا Google اغلب در مورد فناوری های اساسی خود با جزئیات نظر نمی دهد، مگر در موارد نادری مانند Bard یا LaMDA.
مدل های زبان بزرگی که به منابع پیوند دارند
Google اخیراً یک مقاله تحقیقاتی جالب در مورد روشی منتشر کرده است که مدلهای زبان بزرگ را برای اطلاعات خود به منابع استناد میکند. نسخه اولیه مقاله در دسامبر 2022 منتشر شد و نسخه دوم در فوریه 2023 به روز شد.
از دسامبر 2022 به این فناوری آزمایشی گفته میشود.
پیدیاف مقاله را میتوانید از اینجا دانلود کنید: پاسخ به سؤال منتسب: ارزیابی و مدلسازی برای مدلهای زبان بزرگ نسبت داده شده (چکیده Google را اینجا بخوانید).
مقاله پژوهشی هدف این فناوری را بیان میکند:
«مدلهای زبان بزرگ (LLM) نتایج چشمگیری را نشان دادهاند در حالی که نیاز به نظارت مستقیم یا کمی دارند.
علاوه بر این، شواهد فزاینده ای وجود دارد که نشان می دهد LLM ها ممکن است در سناریوهای جستجوی اطلاعات دارای پتانسیل باشند.
ما بر این باوریم که توانایی یک LLM برای نسبت دادن متنی که تولید میکند احتمالاً در این تنظیم بسیار مهم است.
ما QA نسبت داده شده را به عنوان اولین قدم کلیدی در توسعه LLMهای منتسب، فرموله و مطالعه می کنیم.
ما یک چارچوب ارزیابی تکرارپذیر برای کار پیشنهاد میکنیم و مجموعه وسیعی از معماریها را محک میزنیم.
ما حاشیه نویسی های انسانی را به عنوان یک استاندارد طلایی در نظر می گیریم و نشان می دهیم که یک متریک خودکار مرتبط برای توسعه مناسب است.
کار تجربی ما به دو سوال کلیدی پاسخهای مشخصی میدهد (چگونه اسناد را اندازهگیری کنیم؟، و روشهای پیشرفته کنونی در اسناد چقدر خوب عمل میکنند؟)، و نکاتی در مورد نحوه پرداختن به سوال سوم ارائه میدهد. (چگونه LLM ها را با ذکر منبع بسازیم؟).»
این نوع مدل زبان بزرگ میتواند سیستمی را آموزش دهد که بتواند با اسناد پشتیبانی پاسخ دهد که از نظر تئوری اطمینان میدهد که پاسخ بر اساس چیزی است.
مقاله پژوهشی توضیح میدهد:
“برای بررسی این سؤالات، پاسخ به سؤال منتسب (QA) را پیشنهاد می کنیم. در فرمول ما، ورودی به مدل/سیستم یک سؤال است، و خروجی یک جفت (پاسخ، انتساب) است که در آن پاسخ یک رشته پاسخ است، و انتساب یک اشاره گر به یک پیکره ثابت، به عنوان مثال، از پاراگراف ها است.
اسناد بازگردانده شده باید شواهدی برای پاسخ ارائه دهد.”
این فناوری به طور خاص برای وظایف پاسخگویی به سؤالات است.
هدف ایجاد پاسخهای بهتر است – چیزی که گوگل بهطور قابلتوجهی برای بارد میخواهد.
- Attribution به کاربران و توسعه دهندگان این امکان را می دهد که “قابلیت اعتماد و تفاوت ظریف” پاسخ ها را ارزیابی کنند.
- Attribution به توسعه دهندگان این امکان را می دهد که به سرعت کیفیت پاسخ ها را از آنجایی که منابع ارائه شده است بررسی کنند.
یک نکته جالب، فناوری جدیدی به نام AutoAIS است که به شدت با ارزیابهای انسانی مرتبط است.
به عبارت دیگر، این فناوری میتواند کار ارزیابیکنندگان انسانی را خودکار کند و فرآیند رتبهبندی پاسخهای دادهشده توسط یک مدل زبان بزرگ (مانند بارد) را مقیاسبندی کند.
محققان به اشتراک می گذارند:
“ما رتبهبندی انسانی را استاندارد طلایی برای ارزیابی سیستم میدانیم، اما دریافتیم که AutoAIS به خوبی با قضاوت انسان در سطح سیستم ارتباط دارد، و به عنوان یک معیار توسعه که در آن رتبهبندی انسانی غیرممکن است، نویدبخش است. ، یا حتی به عنوان یک سیگنال آموزشی پر سر و صدا. “
این فناوری آزمایشی است. احتمالا مورد استفاده نیست اما یکی از مسیرهایی را نشان می دهد که Google برای تولید پاسخ های قابل اعتماد در حال بررسی است.
مقاله پژوهشی در مورد ویرایش پاسخ ها برای واقعیت
در نهایت، فناوری قابل توجهی در دانشگاه کرنل توسعه یافته است (همچنین به پایان سال 2022 می رسد) که راه متفاوتی را برای ارجاع منبع برای آنچه که یک مدل زبان بزرگ خروجی می دهد بررسی می کند و حتی می تواند پاسخی را برای اصلاح خود ویرایش کند.
>
دانشگاه کرنل (مانند دانشگاه استنفورد) تکنولوژی مربوط به جستجو و سایر زمینه ها را مجوز می دهد و میلیون ها دلار در سال درآمد کسب می کند.
خوب است که با تحقیقات دانشگاهی همراه باشید زیرا نشان می دهد چه چیزی ممکن است و چه چیزی پیشرفته است.
میتوانید PDF مقاله را از اینجا دانلود کنید: RARR: تحقیق و بازبینی چه زبانی مدلها میگویند، با استفاده از مدلهای زبان (و چکیده را اینجا بخوانید).
چکیده این فناوری را توضیح میدهد:
“مدلهای زبان (LMs) اکنون در بسیاری از وظایف مانند یادگیری چند مرحلهای، پاسخگویی به سؤال، استدلال و گفتوگو برتری دارند.
با این حال، آنها گاهی اوقات محتوای پشتیبانی نشده یا گمراه کننده تولید می کنند.
کاربر نمیتواند به راحتی تشخیص دهد که آیا خروجیهایش قابل اعتماد هستند یا خیر، زیرا اکثر LMها هیچ مکانیزم داخلی برای انتساب به شواهد خارجی ندارند.
برای فعال کردن انتساب و در عین حال حفظ تمام مزایای قدرتمند مدلهای نسل اخیر، RARR را پیشنهاد میکنیم (Retrofit Attribution با استفاده از تحقیق و بازبینی)، سیستمی که 1) به طور خودکار برای خروجی هر مدل تولید متن و 2) پست را پیدا میکند. -خروجی را ویرایش می کند تا محتوای پشتیبانی نشده را اصلاح کند و در عین حال خروجی اصلی را تا حد امکان حفظ کند.
…ما دریافتیم که RARR به طور قابل توجهی اسناد را بهبود می بخشد در حالی که در غیر این صورت ورودی اصلی را تا حد بسیار بیشتری نسبت به مدل های ویرایشی که قبلاً بررسی شده بود حفظ می کند.
علاوه بر این، اجرای RARR تنها به تعداد انگشت شماری مثال آموزشی، یک مدل زبان بزرگ و جستجوی استاندارد وب نیاز دارد.
چگونه به Google Bard دسترسی پیدا کنم؟
Google در حال حاضر کاربران جدیدی را برای آزمایش Bard می پذیرد که در حال حاضر به عنوان آزمایشی برچسب گذاری شده است. Google در حال ارائه دسترسی برای Bard در اینجا است.
 عکس از bard.google.com، مارس 2023
عکس از bard.google.com، مارس 2023گوگل سابقه دارد که میگوید بارد جستجو نمیکند، که باید به کسانی که در مورد طلوع هوش مصنوعی احساس اضطراب میکنند، اطمینان دهد.
ما در نقطه عطفی هستیم که شبیه به نقطه عطفی است که شاید در یک دهه دیدهایم.
درک بارد برای هرکسی که در وب منتشر میکند یا سئو را انجام میدهد مفید است، زیرا دانستن محدودیتهای ممکن و آینده چیزهایی که میتوان به دست آورد مفید است.
منابع بیشتر:
تصویر ویژه: Whyredphotographor/Shutterstock
متن کامل در searchenginejournal




